Objective
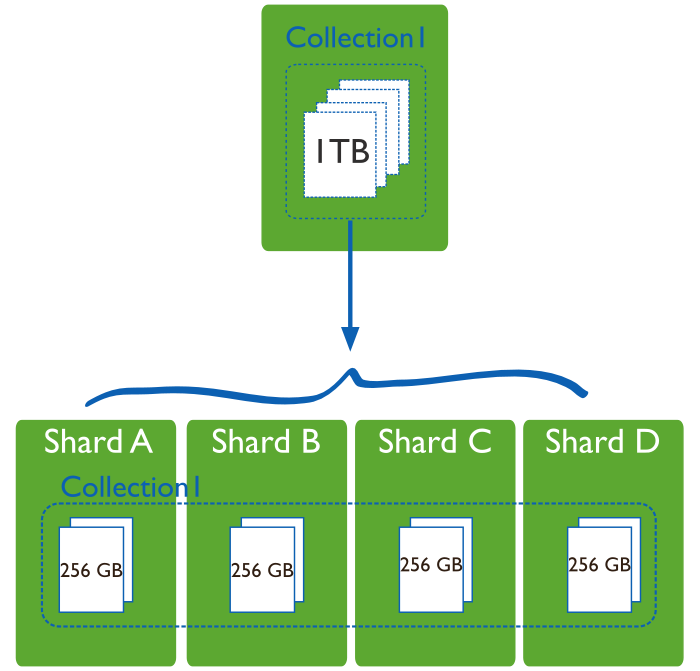
Sharding is a method for partitioning and distributing a large data collection across a cluster of database servers called shards (cf. image below). During this exercise you will learn more about sharding by:
- Configuring a MongoDB cluster for sharding a data collection
- Studying the sharding techniques implemented by MongoDB
Requirements
- SSH client (e.g. Putty for Windows)
- Virtual Machine containing MongoDB (provided during the course)
Configuring a sharded cluster
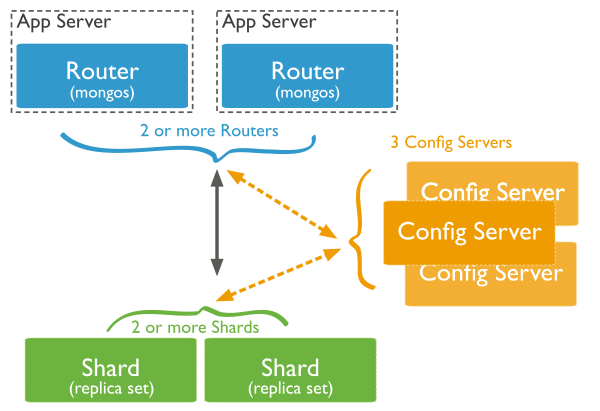
MongoDB supports sharding through the configuration of a sharded cluster. A sharded cluster is composed of the following components (cf. figure below):
- Shards —store the data.
- Query routers —direct operations to the appropriate shard (or shards).
- Config servers —store the cluster’s metadata. The query router uses this metadata to target operations to specific shards.
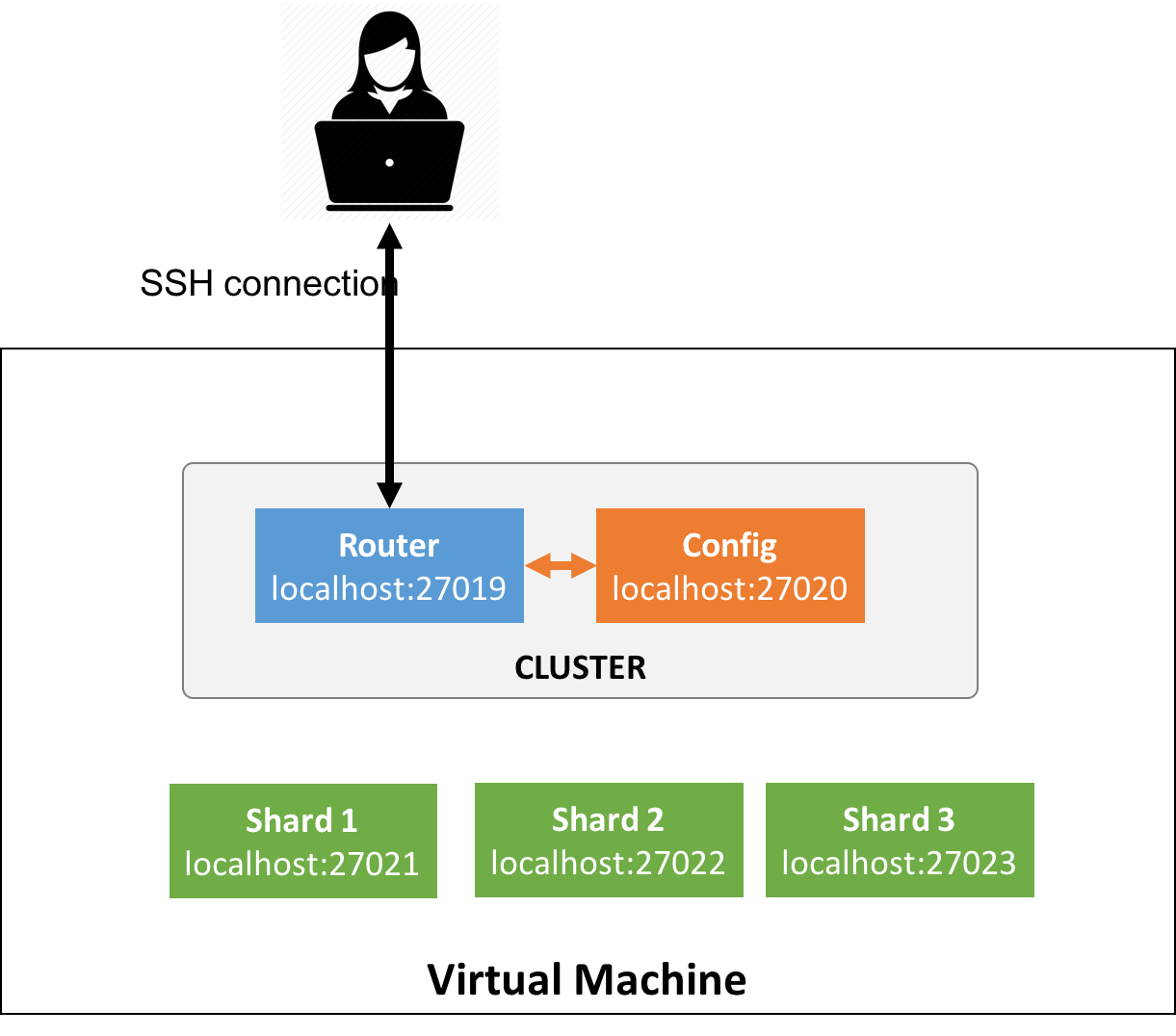
For the sake of simplicity we have pre-configured your virtual machine with a cluster composed of 1 query router and 1 config server (cf. image below).
Adding a shard to the cluster
- Connect to the virtual machine using your SSH client.
- Once connected to the virtual machine, connect to the cluster query router:
mongo --host localhost:27019
- Add a shard to the cluster by executing the following instructions:
use admin
db.runCommand( { addShard: "localhost:27021", name: "shard1" } )
- Verify the state of the cluster:
sh.status()
- Question 2. Which is the important information reported by sh.status() ?
Sharding a database collection
In MongoDB sharding is enabled on a per-basis collection. When sharding is enabled on a collection, MongoDB partitions the collection and distributes its documents across the shards of a cluster using a shard key and a partitioning strategy.
- Range based partitioning: collection is partitioned into ranges [min, max] determined by the shard key. Each range is called a chunk.
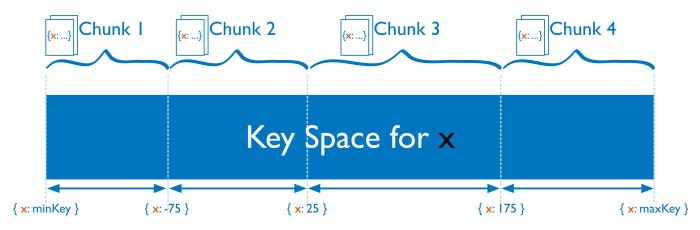
- Hash based partitioning: data is partitioned into chunks using a hash function.
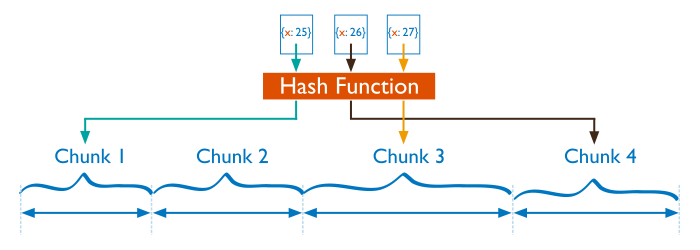
We have pre-configured Shard 1 with a collection called mydb.cities. In what follows you will shard copies of mydb.cities using range based and hash based partitioning.
Range based partitioning
- Create a new collection called mydb.cities1 :
use mydb
db.createCollection("cities1")
show collections
- Enable sharding on mydb.cities1 using the attribute state as shard key :
sh.enableSharding("mydb")
sh.shardCollection("mydb.cities1", { "state": 1} )
- Verify the number of chunks:
sh.status()
- Question 3. How many chunks did you create? Which are their associated ranges? Include a screen copy of the results of the command in your answer to support your answer ?
- Populate mydb.cities1 using the content of mydb.cities:
db.cities.find().forEach( function(d) {
db.cities1.insert(d);
})
- Verify the number of chunks after population:
sh.status()
- Question 4. How many chunks are there now? Which are their associated ranges? Which changes can you identify in particular? Include a screen copy of the results of the command in your answer to support your answer.
Hash-based partitioning
- Create a new collection called mydb.cities2:
db.createCollection("cities2")
show collections
- Enable hashed sharding on mydb.cities2 using the attribute state as shard key.
sh.shardCollection("mydb.cities2", { "state": "hashed"} )
- Verify the number of chunks before populating the new collection.
sh.status()
- Question 5. How many chunks did you create? What differences do you see with respect to the same task in the range sharding strategy? Include a screen copy of the results of the command in your answer to support your answer.
- Populate mydb.cities2 :
db.cities.find().forEach( function(d) {
db.cities2.insert(d); }
)
- Verify the number of chunks after population:
sh.status()
- Question 6. How many chunks are there now? Include a screen copy of the results of the command in your answer to support your answer. Compare the result with respect to the range sharding. Include a screen copy of the results of the command in your answer to support your answer.
Balancing data across a sharded cluster
When a shard has too many chunks compared to other shards, MongoDB automatically redistributes the chunks across the shards. This process is called balancing. In what follows you will analyze the behavior of the MongoDB balancing process by adding more shards to your cluster.
- Add another shard to the cluster:
use admin
db.runCommand( { addShard: "localhost:27022", name: "shard2" } )
- Wait a few seconds and check the status of the cluster:
sh.status()
- Question 7. Draw the new configuration of the cluster and label each element (router, config server and shards) with its corresponding port as you defined in the previous tasks.
Tag aware balancing
MongoDB balancer also supports tagging a range of shard key values. Using tags you can:
- Isolate specific subset of data on a specific set of shards.
- Ensure that relevant data reside on shards that are geographically close to the user.
For the final part of this exercise you will observe the behavior of the MongoDB balancing process when adding tagged shards to your cluster.
- Add a new shard to your cluster:
use admin
db.runCommand( { addShard: "localhost:27023", name: "shard3" } )
sh.status()
- Associate tags to shards:
sh.addShardTag("shard1", "CA")
sh.addShardTag("shard2", "NY")
sh.addShardTag("shard3", "Others")
- Create, shard and populate a new collection named mydb.cities3:
db.createCollection("cities3")
sh.shardCollection("mydb.cities3", { "state": 1} )
use mydb
db.cities.find().forEach( function(d) {
db.cities3.insert(d);
})
- Associate shard key ranges to tagged shards:
sh.addTagRange("mydb.cities3", { state: MinKey }, { state: "CA" }, "Others")
sh.addTagRange("mydb.cities3", { state: "CA" }, { state: "CA_" }, "CA")
sh.addTagRange("mydb.cities3", { state: "CA_" }, { state: "NY" }, "Others")
sh.addTagRange("mydb.cities3", { state: "NY" }, { state: "NY_" }, "NY")
sh.addTagRange("mydb.cities3", { state: "NY_" }, { state: MaxKey }, "Others")
- Display cluster information:
sh.status()
- Question 8. Analyze the results and explain the logic behind this tagging strategy. Connect to the shard that contains the data about California, and count the documents. Do the same operation with the other shards. Is the sharded data collection complete with respect to initial one? Are shards orthogonal?